Blog posts
The blog posts are also shared through on R-bloggers.In this tutorial I’ll explain the concept behind Principal Component Analysis, and with an example I’ll show you how to perform a PCA, how to choose the principal components and how to interpret them. Read more… You can download the script here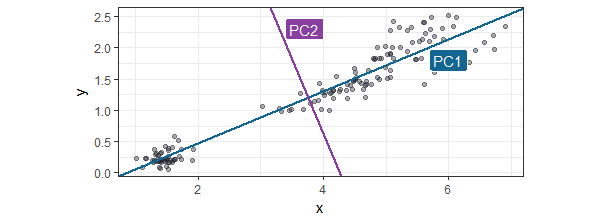 Principal Component Analysis (PCA) is a method for reducing a data-set with a high number of variables to a smaller set of new variables, ‘juicing’ the most of the same information out of the whole set of variables. In the data science realm it is mostly used to achieve one or more of the following goals:
Principal Component Analysis (PCA) is a method for reducing a data-set with a high number of variables to a smaller set of new variables, ‘juicing’ the most of the same information out of the whole set of variables. In the data science realm it is mostly used to achieve one or more of the following goals:
You can download the script here. This tutorial we’ll be text-mining Lewis Carol’s Alice’s Adventures in Wonderland by using the gutenbergr, tidytext and ggplot2 libraries. I’ve assumed that you know some basic stuff about the tidyverse and ggplot2 libraries. First I’ll discuss the concepts that drove the script, after which I’ll jump into the scripting and of these concepts and their results. Read more…
This tutorial we’ll be text-mining Lewis Carol’s Alice’s Adventures in Wonderland by using the gutenbergr, tidytext and ggplot2 libraries. I’ve assumed that you know some basic stuff about the tidyverse and ggplot2 libraries. First I’ll discuss the concepts that drove the script, after which I’ll jump into the scripting and of these concepts and their results. Read more…